NoSql概述 什么是NoSql NoSql=Not Only SQL,不仅仅是SQL
泛指非关系型数据库
NOSQL特点
方便扩展(数据之间没有好关系)
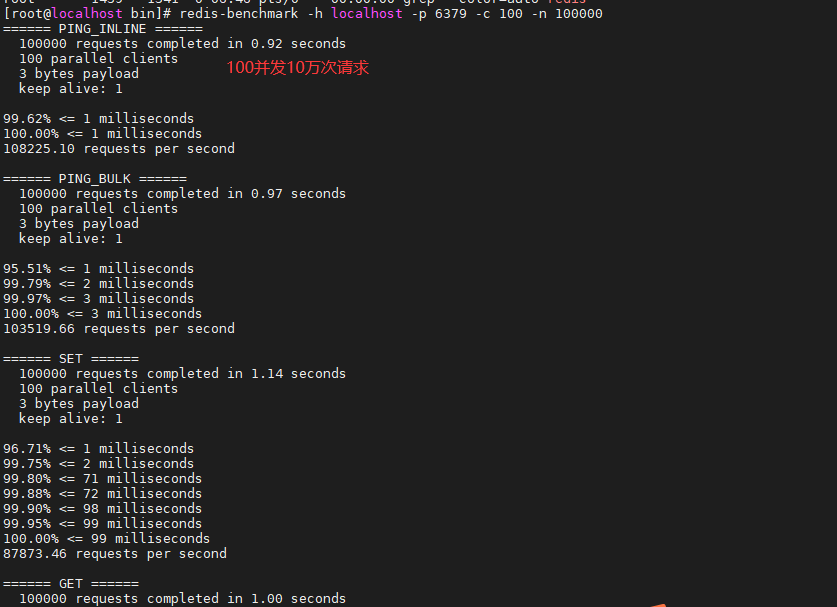
大数据量高性能(Redis一秒写入8万次,读取11万次)
数据类型是多样型的
NoSQL四大分类 K-V键值对:
文档型数据库:
列存储数据库:
图关系数据库:
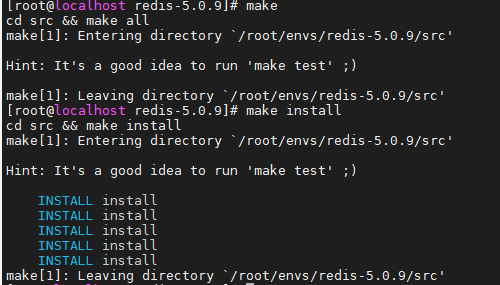
Redis入门 1.下载redis-5.0.9.tar.gz
2.解压
1 tar -zxvf redis-5.0.9.tar.gz
3.进入解压后的文件夹,可以看到redis配置文件
4.基本环境安装
没有error就是成功了
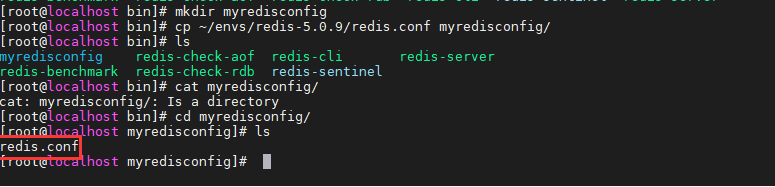
5.redis默认安装路径/usr/local/bin
6.复制一个配置文件
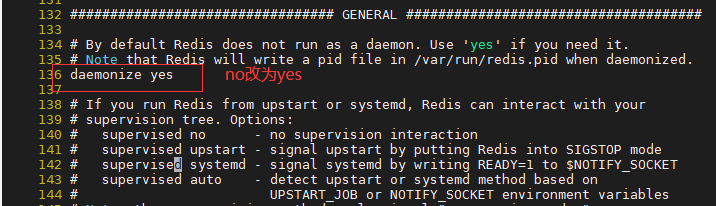
7.修改配置文件,136行左右,设置为后台启动(守护线程)
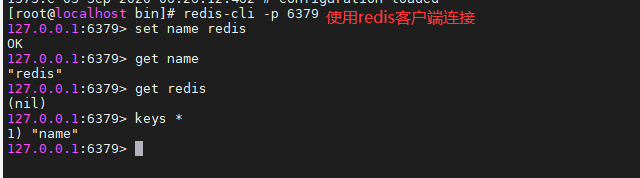
8.启动redis服务,通过指定的配置文件启动服务
9.使用redis-cli进行连接测试
10.查看redis进程
11.关闭redis服务
redis-benchmark性能测试 redis 性能测试的基本命令如下:
1 redis-benchmark [option] [option value]
redis 性能测试工具可选参数如下所示:
序号
选项
描述
默认值
1
-h 指定服务器主机名
127.0.0.1
2
-p 指定服务器端口
6379
3
-s 指定服务器 socket
4
-c 指定并发连接数
50
5
-n 指定请求数
10000
6
-d 以字节的形式指定 SET/GET 值的数据大小
2
7
-k 1=keep alive 0=reconnect
1
8
-r SET/GET/INCR 使用随机 key, SADD 使用随机值
9
-P 通过管道传输 请求
1
10
-q 强制退出 redis。仅显示 query/sec 值
11
–csv 以 CSV 格式输出
12
-l 生成循环,永久执行测试
13
-t 仅运行以逗号分隔的测试命令列表。
14
-I Idle 模式。仅打开 N 个 idle 连接并等待。
1 2 redis-benchmark -h localhost -p 6379 -c 100 -n 100000
Redis数据类型
用作数据库、缓存、消息中间件
Reids Keys 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 127.0.0.1:6379> keys * (empty list or set ) 127.0.0.1:6379> set name aurora OK 127.0.0.1:6379> keys * 1) "name" 127.0.0.1:6379> exists name (integer ) 1 127.0.0.1:6379> exists name1 (integer ) 0 127.0.0.1:6379> move name 1 (integer ) 1 127.0.0.1:6379> keys * (empty list or set ) 127.0.0.1:6379> set age 1 OK 127.0.0.1:6379> keys * 1) "age" 127.0.0.1:6379> set name aurora OK 127.0.0.1:6379> clear 127.0.0.1:6379> 127.0.0.1:6379> keys * 1) "name" 2) "age" 127.0.0.1:6379> get name "aurora" 127.0.0.1:6379> EXPIRE name 10 (integer ) 1 127.0.0.1:6379> keys * 1) "name" 2) "age" 127.0.0.1:6379> ttl name (integer ) 1 127.0.0.1:6379> ttl name (integer ) -2 127.0.0.1:6379> get name (nil) 127.0.0.1:6379> type age string 127.0.0.1:6379>
Strings(字符串) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 127.0.0.1:6379> set key1 v1 OK 127.0.0.1:6379> get key1 "v1" 127.0.0.1:6379> EXISTS key1 (integer ) 1 127.0.0.1:6379> APPEND key1 hello (integer ) 7 127.0.0.1:6379> get key1 "v1hello" 127.0.0.1:6379> STRLEN key1 (integer ) 7 127.0.0.1:6379> APPEND key1 111111111 (integer ) 16 127.0.0.1:6379> STRLEN key1 (integer ) 16 127.0.0.1:6379> 127.0.0.1:6379> APPEND name aurora (integer ) 6 127.0.0.1:6379> keys * 1) "name" 2) "key1" 3) "age" 127.0.0.1:6379> ++和--操作 127.0.0.1:6379> set views 0 OK 127.0.0.1:6379> get views "0" 127.0.0.1:6379> INCR views (integer ) 1 127.0.0.1:6379> get views "1" 127.0.0.1:6379> INCR views (integer ) 2 127.0.0.1:6379> INCR views (integer ) 3 127.0.0.1:6379> get views "3" 127.0.0.1:6379> DECR views (integer ) 2 127.0.0.1:6379> DECR views (integer ) 1 127.0.0.1:6379> get views "1" 127.0.0.1:6379> 127.0.0.1:6379> INCRBY views 10 (integer ) 11 127.0.0.1:6379> get viw (nil) 127.0.0.1:6379> get views "11" 127.0.0.1:6379> DECRBY views 11 (integer ) 0 127.0.0.1:6379> get views "0" 127.0.0.1:6379> 127.0.0.1:6379> set key1 hello,world OK 127.0.0.1:6379> get key1 "hello,world" 127.0.0.1:6379> GETRANGE key1 0 3 "hell" 127.0.0.1:6379> GETRANGE key1 0 -1 "hello,world" 127.0.0.1:6379> 127.0.0.1:6379> set key2 abcdefg OK 127.0.0.1:6379> SETRANGE key2 1 xxx (integer ) 7 127.0.0.1:6379> get key2 "axxxefg" 127.0.0.1:6379> setex setnx 127.0.0.1:6379> SETEX key3 30 helloclear OK 127.0.0.1:6379> ttl key3 (integer ) 26 127.0.0.1:6379> ttl key3 (integer ) 24 127.0.0.1:6379> ttl key3 (integer ) 23 127.0.0.1:6379> ttl key3 (integer ) -2 127.0.0.1:6379> 127.0.0.1:6379> SETNX key4 redis (integer ) 1 127.0.0.1:6379> keys * 1) "key4" 2) "key2" 3) "key1" 127.0.0.1:6379> SETNX key4 redis22222 (integer ) 0 127.0.0.1:6379> get key4 "redis" 127.0.0.1:6379> mset mget 127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 OK 127.0.0.1:6379> keys * 1) "k3" 2) "k2" 3) "k1" 127.0.0.1:6379> mget k1 k2 1) "v1" 2) "v2" 127.0.0.1:6379> MSETNX k1 v1 k4 v4 (integer ) 0 127.0.0.1:6379> keys * 1) "k3" 2) "k2" 3) "k1" 127.0.0.1:6379> 对象 set user:1 {name:zhangsan,age:3} 127.0.0.1:6379> mset user:1:name zhangsan user:1:age 18 OK 127.0.0.1:6379> mget user:1:name user:1:age 1) "zhangsan" 2) "18" 127.0.0.1:6379> getset 127.0.0.1:6379> getset db redis (nil) 127.0.0.1:6379> get db "redis" 127.0.0.1:6379> getset db mysql "redis" 127.0.0.1:6379> get db "mysql" 127.0.0.1:6379>
Lists(列表) 按插入顺序排序的字符串元素的集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 LPUSH RPUSH LRANGE 127.0.0.1:6379> LPUSH list one (integer ) 1 127.0.0.1:6379> LPUSH list two (integer ) 2 127.0.0.1:6379> LPUSH list three (integer ) 3 127.0.0.1:6379> LRANGE list 0 -1 1) "three" 2) "two" 3) "one" 127.0.0.1:6379> LRANGE list 0 1 1) "three" 2) "two" 127.0.0.1:6379> RPUSH list four (integer ) 4 127.0.0.1:6379> LRANGE list 0 -1 1) "three" 2) "two" 3) "one" 4) "four" LPOP RPOP 127.0.0.1:6379> LRANGE list 0 -1 1) "three" 2) "two" 3) "one" 4) "four" 127.0.0.1:6379> LPOP list "three" 127.0.0.1:6379> LRANGE list 0 -1 1) "two" 2) "one" 3) "four" 127.0.0.1:6379> RPOP list "four" 127.0.0.1:6379> LRANGE list 0 -1 1) "two" 2) "one" 127.0.0.1:6379> LINDEX 127.0.0.1:6379> LINDEX list 0 "two" 127.0.0.1:6379> LINDEX list 1 "one" 127.0.0.1:6379> LLEN 127.0.0.1:6379> flushdb OK 127.0.0.1:6379> LPUSH list one (integer ) 1 127.0.0.1:6379> LPUSH list one2 (integer ) 2 127.0.0.1:6379> LPUSH list one3 (integer ) 3 127.0.0.1:6379> LLEN list (integer ) 3 127.0.0.1:6379> LREM 127.0.0.1:6379> LPUSH list one (integer ) 4 127.0.0.1:6379> LRANGE list 0 -1 1) "one" 2) "one3" 3) "one2" 4) "one" 127.0.0.1:6379> LREM list 1 one2 (integer ) 1 127.0.0.1:6379> LRANGE list 0 -1 1) "one" 2) "one3" 3) "one" 127.0.0.1:6379> LREM list 2 one (integer ) 2 127.0.0.1:6379> LRANGE list 0 -1 1) "one3" 127.0.0.1:6379> LTRIM 127.0.0.1:6379> LPUSH mylist hello2 (integer ) 3 127.0.0.1:6379> LPUSH mylist hello3 (integer ) 4 127.0.0.1:6379> LPUSH mylist hello4 (integer ) 5 127.0.0.1:6379> LPUSH mylist hello5 hello6 (integer ) 7 127.0.0.1:6379> LRANGE mylist 0 -1 1) "hello6" 2) "hello5" 3) "hello4" 4) "hello3" 5) "hello2" 6) "hello1" 7) "hello" 127.0.0.1:6379> LTRIM mylist 1 2 OK 127.0.0.1:6379> LRANGE mylist 0 -1 1) "hello5" 2) "hello4" RPOPLPUSH 127.0.0.1:6379> FLUSHALL OK 127.0.0.1:6379> clear 127.0.0.1:6379> LPUSH mysqlist hello hello1 hello2 (integer ) 3 127.0.0.1:6379> LRANGE mylist 0 -1 (empty list or set ) 127.0.0.1:6379> LRANGE mysqlist 0 -1 1) "hello2" 2) "hello1" 3) "hello" 127.0.0.1:6379> RPOPLPUSH mysqlist otherlist "hello" 127.0.0.1:6379> LRANGE mysqlist 0 -1 1) "hello2" 2) "hello1" 127.0.0.1:6379> LRANGE otherlist 0 -1 1) "hello" LSET 127.0.0.1:6379> FLUSHALL OK 127.0.0.1:6379> clear 127.0.0.1:6379> EXISTS list (integer ) 0 127.0.0.1:6379> LSET list 0 aa (error) ERR no such key 127.0.0.1:6379> LPUSH list bb (integer ) 1 127.0.0.1:6379> LSET list 0 aa OK 127.0.0.1:6379> LRANGE list 0 -1 1) "aa" 127.0.0.1:6379> LSET list 1 aa (error) ERR index out of range 127.0.0.1:6379> LINSERT 127.0.0.1:6379> LPUSH list hello word (integer ) 2 127.0.0.1:6379> LINSERT list before word , (integer ) 3 127.0.0.1:6379> LRANGE list 0 -1 1) "," 2) "word" 3) "hello" 127.0.0.1:6379> LINSERT list after word new (integer ) 4 127.0.0.1:6379> LRANGE list 0 -1 1) "," 2) "word" 3) "new" 4) "hello" 127.0.0.1:6379>
Lists实际上是一个链表,基于Linked LIsts实现,所以插效率非常高,但是访问效率并不是特别高,快速访问集合后面会有sorted setskey会自动创建,在插入元素时key不存在会自动创建空list,当我们移除元素时,如果值是空的,key会被自动销毁
Sets(集合) 不重复且无序的字符串元素的集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 127.0.0.1:6379> sadd myset "hello" (integer ) 1 127.0.0.1:6379> sadd myset "1111" (integer ) 1 127.0.0.1:6379> sadd myset "aurora" (integer ) 1 127.0.0.1:6379> SMEMBERS myset 1) "1111" 2) "hello" 3) "aurora" 127.0.0.1:6379> SMEMBERS myset 1) "1111" 2) "hello" 3) "aurora" 127.0.0.1:6379> SISMEMBER myset hello (integer ) 1 127.0.0.1:6379> SISMEMBER myset h (integer ) 0 SCARD 127.0.0.1:6379> SADD myset hello (integer ) 1 127.0.0.1:6379> SADD myset hello1 (integer ) 1 127.0.0.1:6379> SADD myset hello2 (integer ) 1 127.0.0.1:6379> SADD myset hello (integer ) 0 127.0.0.1:6379> SCARD myset (integer ) 3 127.0.0.1:6379> SREM 127.0.0.1:6379> SREM myset hello (integer ) 1 127.0.0.1:6379> SCARD myset (integer ) 2 127.0.0.1:6379> SMEMBERS myset 1) "hello1" 2) "hello2" 127.0.0.1:6379> SRANDMEMBER 127.0.0.1:6379> SRANDMEMBER myset "hello2" (1.52s) 127.0.0.1:6379> SRANDMEMBER myset "hello1" 127.0.0.1:6379> SRANDMEMBER myset "hello2" 127.0.0.1:6379> SRANDMEMBER myset "hello1" 127.0.0.1:6379> SRANDMEMBER myset 2 1) "hello1" 2) "hello2" SPOP 127.0.0.1:6379> SADD myset he (integer ) 1 127.0.0.1:6379> SMEMBERS myset 1) "hello1" 2) "he" 3) "hello2" 127.0.0.1:6379> SPOP myset "he" 127.0.0.1:6379> SMEMBERS myset 1) "hello1" 2) "hello2" SMOVE 127.0.0.1:6379> SADD myset hello (integer ) 1 127.0.0.1:6379> SADD myset world (integer ) 1 127.0.0.1:6379> SADD myset 22 (integer ) 1 127.0.0.1:6379> SADD myset2 nihao (integer ) 1 127.0.0.1:6379> SMEMBERS myset 1) "hello" 2) "22" 3) "world" 127.0.0.1:6379> SMEMBERS myset2 1) "nihao" 127.0.0.1:6379> SMOVE myset myset2 22 (integer ) 1 127.0.0.1:6379> SMEMBERS myset 1) "hello" 2) "world" 127.0.0.1:6379> SMEMBERS myset2 1) "22" 2) "nihao" INTER DIFF UNION 127.0.0.1:6379> SADD key1 a (integer ) 1 127.0.0.1:6379> SADD key1 b (integer ) 1 127.0.0.1:6379> SADD key1 c (integer ) 1 127.0.0.1:6379> SADD key2 c (integer ) 1 127.0.0.1:6379> SADD key2 d (integer ) 1 127.0.0.1:6379> SADD key2 e (integer ) 1 127.0.0.1:6379> SMEMBERS key1 1) "c" 2) "b" 3) "a" 127.0.0.1:6379> SMEMBERS key2 1) "e" 2) "d" 3) "c" 127.0.0.1:6379> SINTER key1 key2 1) "c" 127.0.0.1:6379> SDIFF key1 key2 1) "a" 2) "b" 127.0.0.1:6379> SUNION key1 key2 1) "c" 2) "a" 3) "b" 4) "e" 5) "d"
Hashes(哈希) Map集合 key-map
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 HSET HGET HMSET HGETALL 127.0.0.1:6379> HSET myhash k1 v1 (integer ) 1 127.0.0.1:6379> HGET myhash k1 "v1" 127.0.0.1:6379> HMSET myhash k1 v1 k2 v2 k3 v3 OK 127.0.0.1:6379> HMGET myhash k1 k2 k3 1) "v1" 2) "v2" 3) "v3" 127.0.0.1:6379> HGETALL myhash 1) "k1" 2) "v1" 3) "k2" 4) "v2" 5) "k3" 6) "v3" 127.0.0.1:6379> HDEL myhash k1 (integer ) 1 127.0.0.1:6379> HGETALL myhash 1) "k2" 2) "v2" 3) "k3" 4) "v3" HLEN 127.0.0.1:6379> HLEN myhash (integer ) 2 HEXISTS 127.0.0.1:6379> HEXISTS myhash k1 (integer ) 0 127.0.0.1:6379> HEXISTS myhash k2 (integer ) 1 HKEYS HVALS 127.0.0.1:6379> HKEYS myhash 1) "k2" 2) "k3" 127.0.0.1:6379> HVALS myhash 1) "v2" 2) "v3" 127.0.0.1:6379> HINCRBY 127.0.0.1:6379> HMSET myhash k1 5 k2 9 OK 127.0.0.1:6379> HINCRBY myhash k1 1 (integer ) 6 127.0.0.1:6379> HINCRBY myhash k2 -1 (integer ) 8
Zset(有序集合) 有序不重复
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 ZADD ZRANGE 127.0.0.1:6379> ZADD myset 1 one 2 two 3 three (integer ) 3 127.0.0.1:6379> ZRANGE myset 0 -1 1) "one" 2) "two" 3) "three" 127.0.0.1:6379> zadd salar 1000 zh (integer ) 1 127.0.0.1:6379> zadd salar 100 zh2 (integer ) 1 127.0.0.1:6379> zadd salar 10000 zh3 (integer ) 1 127.0.0.1:6379> ZRANGE salar 0 -1 1) "zh2" 2) "zh" 3) "zh3" 127.0.0.1:6379> ZRANGEBYSCORE salar -inf +inf 1) "zh2" 2) "zh" 3) "zh3" 127.0.0.1:6379> ZREVRANGE salar 0 -1 1) "zh3" 2) "zh2" 127.0.0.1:6379> ZRANGEBYSCORE salar -inf +inf withscores 1) "zh2" 2) "100" 3) "zh" 4) "1000" 5) "zh3" 6) "10000" ZREM ZCARD 127.0.0.1:6379> ZREM salar zh (integer ) 1 127.0.0.1:6379> ZRANGE salar 0 -1 1) "zh2" 2) "zh3" 127.0.0.1:6379> ZCARD salar (integer ) 2 ZCOUNT 127.0.0.1:6379> ZADD myset 1 h 2 j 3 k (integer ) 3 127.0.0.1:6379> ZCOUNT myset 1 2 (integer ) 2 127.0.0.1:6379> ZCOUNT myset 1 3 (integer ) 3
Geospatial(地理位置) Redis在3.2推出了deospatial,这个功能可以推算出地理位置的信息,两地之间的距离
GEOADD
1 2 3 4 5 6 7 8 127.0.0.1:6379> GEOADD china:city 114.279 30.573 wuhan 115.073 31.234 macheng 121.4445 31.213 shanghai (integer ) 3 127.0.0.1:6379> GEOADD china:city 113.265 23.108 guangzhou 114.109 22.544 shenzhen 116.408 39.904 beijing (integer ) 3
GEOPOS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0.0.1:6379> GEOPOS china:city wuhan 1) 1) "114.27899926900863647" 2) "30.57299931525717795" 127.0.0.1:6379> GEOPOS china:city wuhan macheng baijing 1) 1) "114.27899926900863647" 2) "30.57299931525717795" 2) 1) "115.07299751043319702" 2) "31.23399882974727149" 3) (nil) 127.0.0.1:6379> GEOPOS china:city wuhan macheng beijing 1) 1) "114.27899926900863647" 2) "30.57299931525717795" 2) 1) "115.07299751043319702" 2) "31.23399882974727149" 3) 1) "116.40800267457962036" 2) "39.90399988166036138"
GEODIST
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 127.0.0.1:6379> GEODIST china:city wuhan macheng "105579.8472" 127.0.0.1:6379> GEODIST china:city wuhan macheng m "105579.8472" 127.0.0.1:6379> GEODIST china:city wuhan macheng km "105.5798" 127.0.0.1:6379> GEODIST china:city macheng shanghai "605948.1978" 127.0.0.1:6379> GEODIST china:city macheng shanghai km "605.9482" 127.0.0.1:6379> GEODIST china:city macheng shanghai mi "376.5197" 127.0.0.1:6379> GEODIST china:city macheng shanghai ft "1988019.0215" 127.0.0.1:6379> GEODIST china:city macheng shangh (nil)
GEORADIUS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km 1) "shenzhen" 2) "guangzhou" 3) "wuhan" 4) "macheng" 127.0.0.1:6379> GEORADIUS china:city 110 30 500 km 1) "wuhan" 127.0.0.1:6379> GEORADIUS china:city 110 30 800 km 1) "wuhan" 2) "macheng" 127.0.0.1:6379> GEORADIUS china:city 110 30 800 km withcoord 1) 1) "wuhan" 2) 1) "114.27899926900863647" 2) "30.57299931525717795" 2) 1) "macheng" 2) 1) "115.07299751043319702" 2) "31.23399882974727149" 127.0.0.1:6379> GEORADIUS china:city 110 30 800 km withdist 1) 1) "wuhan" 2) "415.8636" 2) 1) "macheng" 2) "504.5558" 127.0.0.1:6379> GEORADIUS china:city 110 30 800 km ASC 1) "wuhan" 2) "macheng" 127.0.0.1:6379> GEORADIUS china:city 110 30 800 km DESC 1) "macheng" 2) "wuhan" 127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km 1) "shenzhen" 2) "guangzhou" 3) "wuhan" 4) "macheng" 127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km COUNT 2 1) "wuhan" 2) "macheng" 127.0.0.1:6379>
GEORADIUSBYMENBER
1 2 3 4 5 6 7 8 127.0.0.1:6379> GEORADIUSBYMEMBER china:city macheng 500 km 1) "wuhan" 2) "macheng" 127.0.0.1:6379> GEORADIUSBYMEMBER china:city macheng 800 km 1) "wuhan" 2) "macheng" 3) "shanghai"
GEOHASH
1 2 3 4 5 6 7 8 9 10 11 12 13 127.0.0.1:6379> GEOHASH china:city macheng wuhan 1) "wt9cdtcx5p0" 2) "wt3mbmxkts0" 127.0.0.1:6379> GEOHASH china:city macheng shanghai 1) "wt9cdtcx5p0" 2) "wtw3ed1hvv0" 127.0.0.1:6379> GEOHASH china:city wuhan shanghai 1) "wt3mbmxkts0" 2) "wtw3ed1hvv0"
GEO底层实现原理是Zset,我们可以用Zset命令来操作geo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0.0.1:6379> ZRANGE china:city 0 -1 1) "shenzhen" 2) "guangzhou" 3) "wuhan" 4) "macheng" 5) "shanghai" 6) "beijing" 127.0.0.1:6379> ZREM china:city shenzhen (integer ) 1 127.0.0.1:6379> ZRANGE china:city 0 -1 1) "guangzhou" 2) "wuhan" 3) "macheng" 4) "shanghai" 5) "beijing" 127.0.0.1:6379>
Hyperloglog(基数)
基数(一个集合内不重复的元素个数)
A{1,3,4,5,4,7,2} 基数=6
简介
Redis Hyperloglog 基数统计的算法,它是一种概率数据结构
缺点:小于1的错误率
网页的UV(一个人访问一个网站多次,还是算作一个人)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 127.0.0.1:6379> PFADD key1 a b c d e f g (integer ) 1 127.0.0.1:6379> PFADD key2 a b t y u (integer ) 1 127.0.0.1:6379> PFCOUNT key1 (integer ) 7 127.0.0.1:6379> PFCOUNT key2 (integer ) 5 127.0.0.1:6379> PFMERGE key3 key1 key2 OK 127.0.0.1:6379> PFCOUNT key3 (integer ) 9 127.0.0.1:6379>
Bitmaps(位图)
位图,不是一种实际的数据结,只有0和1两个状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 127.0.0.1:6379> SETBIT sign 0 1 (integer ) 0 127.0.0.1:6379> SETBIT sign 1 0 (integer ) 0 127.0.0.1:6379> SETBIT sign 2 0 (integer ) 0 127.0.0.1:6379> SETBIT sign 3 0 (integer ) 0 127.0.0.1:6379> SETBIT sign 4 1 (integer ) 0 127.0.0.1:6379> SETBIT sign 5 1 (integer ) 0 127.0.0.1:6379> SETBIT sign 6 1 (integer ) 0 127.0.0.1:6379> GETBIT sign 3 (integer ) 0 127.0.0.1:6379> GETBIT sign 6 (integer ) 1 127.0.0.1:6379> BITCOUNT sign (integer ) 4
Redis事务
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
事务是一个原子操作,事务中的命令要么全部被执行,要么全部不执行(严格来说单个命令是原子操作,多个就不一定)
没有隔离级别的概念
开启事务后的命令不会立刻执行,会加入队列,在执行事务的时候才会执行
开启事务->入队列->执行事务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> MSET k2 v2 k3 v3 QUEUED 127.0.0.1:6379> MGET k2 k3 QUEUED 127.0.0.1:6379> set k4 5 QUEUED 127.0.0.1:6379> EXEC 1) OK 2) OK 3) 1) "v2" 2) "v3" 4) OK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set k5 v5 QUEUED 127.0.0.1:6379> DISCARD OK 127.0.0.1:6379> get v5 (nil) 127.0.0.1:6379> keys * 1) "k3" 2) "k4" 3) "k2" 4) "k1"
事务中的错误
在事务执行前,入队的命令可能会出错,出错后事务执行时会放弃事务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set k1 v1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> getset k2 (error) ERR wrong number of arguments for 'getset' command 127.0.0.1:6379> set k3 v3 QUEUED 127.0.0.1:6379> EXEC (error) EXECABORT Transaction discarded because of previous errors. 127.0.0.1:6379> get k1 (nil)
在事务执行后,产生的错误,并不会影响事务,其他命令依旧执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> INCR k1 QUEUED 127.0.0.1:6379> set k2 v2 QUEUED 127.0.0.1:6379> EXEC 1) (error) ERR value is not an integer or out of range 2) OK 127.0.0.1:6379> MGET k1 k2 1) "v1" 2) "v2" 127.0.0.1:6379>
WATCH
WATCH可以为Reids提供check-and-set(CAS
)行为。被WATCH的键会被监视, 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply 来表示事务已经失败
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 127.0.0.1:6379> set k1 100 OK 127.0.0.1:6379> set k2 0 OK 127.0.0.1:6379> WATCH k1 OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> DECRBY k1 20 QUEUED 127.0.0.1:6379> INCRBY k2 20 QUEUED 127.0.0.1:6379> EXEC 1) (integer ) 80 2) (integer ) 20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 127.0.0.1:6379> WATCH k1 OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> DECRBY k1 20 QUEUED 127.0.0.1:6379> INCRBY k2 20 QUEUED 127.0.0.1:6379> get k1 "80" 127.0.0.1:6379> set k1 800 OK 127.0.0.1:6379> EXEC (nil) 127.0.0.1:6379> MGET k1 k2 1) "800" 2) "20"
如果在 WATCH 执行之后, EXEC 执行之前, 有其他客户端修改了 mykey 的值, 那么当前客户端的事务就会失败,这种形式就被称作乐观锁
取消监视
当 EXEC 被调用时, 不管事务是否成功执行, 对所有键的监视都会被取消。
当客户端断开连接时, 该客户端对键的监视也会被取消。
使用无参数的 UNWATCH 命令可以手动取消对所有键的监视
Jeids
Jedis是Redis官方推荐的Java连接工具,使用Java操作Redis中间件。
使用Java操作Redis一定要对Jedis十分熟悉
异常:
Exception in thread "main" redis.clients.jedis.exceptions.JedisConnectionException: Failed connecting to 192.168.45.113:6379
关闭防火墙
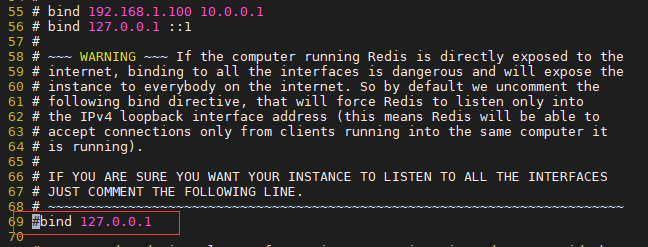
redis.conf 69行左右注释掉
异常:
Exception in thread "main" redis.clients.jedis.exceptions.JedisDataException: DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password
关闭保护模式!
常用API Strings
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 package cn.this52.main;import redis.clients.jedis.Jedis;import java.util.List;import java.util.Set;public class StringsTest public static void main (String[] args) throws InterruptedException try (Jedis jedis = new Jedis("192.168.45.113" )) { String s = jedis.flushDB(); System.out.println("清空数据库:" + s); String k1 = jedis.set("k1" , "v1" ); System.out.println("返回值:" + k1); String v1 = jedis.get("k1" ); System.out.println("v1:" + v1); System.err.println("************************" ); String kv = jedis.mset("k2" , "2" , "k3" , "33" ); System.out.println("批量设置:" + kv); List<String> mget = jedis.mget("k2" , "k3" ); mget.forEach(k -> System.out.println("k:" + k)); Long k21 = jedis.incrBy("k2" , 10 ); Long k31 = jedis.incr("k3" ); System.out.println("k2自增10:" + k21); System.out.println("k3自增1:" + k31); Long k22 = jedis.decr("k2" ); System.out.println("k2自减1:" + k22); System.out.println(); Boolean k2 = jedis.exists("k2" ); System.out.println("k2是否存在:" + k2); Set<String> keys = jedis.keys("*" ); System.out.println("所有的key:" + keys); Long k3 = jedis.setnx("k3" , "3" ); System.out.println("k3不存在时设置k3=3,结果:" + k3); System.out.println("k3:" + jedis.get("k3" )); String k4 = jedis.setex("k4" , 10 , "4" ); System.out.println("设置一个字符串k4=4,过期时间为30s:" + k4); Thread.sleep(1000 ); System.out.println("k4剩余时间:" + jedis.ttl("k4" )); System.out.println("k4剩余时间:" + jedis.ttl("k4" )); Thread.sleep(3000 ); System.out.println("k4剩余时间:" + jedis.ttl("k4" )); System.out.println("k4剩余时间:" + jedis.ttl("k4" )); Long k11 = jedis.expire("k1" , 10 ); System.out.println("expire设置过期时间:" + k11); String k23 = jedis.getSet("k2" , "111" ); System.out.println("getset:" + k23); System.out.println("k2=" + jedis.get("k2" )); System.out.println(); System.out.println(); String set = jedis.set("h1" , "hello" ); String set2 = jedis.set("h2" , "world" ); System.out.println("h1=" + jedis.get("h1" )); System.out.println("h2=" + jedis.get("h2" )); Long hello = jedis.strlen("h1" ); System.out.println("strlen结果:" + hello); Long append = jedis.append("h1" , jedis.get("h2" )); System.out.println("将h2append到h1上,结果:" + append); System.out.println("h1=" + jedis.get("h1" )); System.out.println("h2=" + jedis.get("h2" )); String h1 = jedis.getrange("h1" , 0 , 3 ); System.out.println("截取h1[0,3]结果:" + h1); String h2 = jedis.getrange("h1" , 0 , -1 ); System.out.println("截取h1[0,-1]结果:" + h2); Long setrange = jedis.setrange("h2" , 3 , "ll" ); System.out.println("覆盖h2索引从3开始的值:" + setrange); System.out.println("h2=" + jedis.get("h2" )); } } }
Lists
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 >package cn.this52.main; >import redis.clients.jedis.Jedis; >import redis.clients.jedis.ListPosition; >import java.util.List; >public class ListsTest public static void main (String[] args) Long del; try (Jedis jedis = new Jedis("192.168.45.113" )) { jedis.flushDB(); Long list1 = jedis.lpush("list1" , "1" , "2" , "3" , "5" , "1" ); System.out.println("lpush结果:" + list1); List<String> list11 = jedis.lrange("list1" , 0 , 2 ); List<String> list12 = jedis.lrange("list1" , 0 , -1 ); System.out.println("lrange[0,2]结果:" + list11); System.out.println("lrange[0,-1]结果:" + list12); Long rpush = jedis.rpush("list1" , "33" , "44" ); System.out.println("rpush结果:" + rpush); System.out.println(jedis.lrange("list1" , 0 , -1 )); String lsit1 = jedis.type("list1" ); System.out.println("list1类型=" + lsit1); System.out.println("所有key" + jedis.keys("*" )); String list13 = jedis.lpop("list1" ); System.out.println("弹出list1列表的第一个值:" + list13); String list14 = jedis.rpop("list1" ); System.out.println("弹出list1列表的最后一个值:" + list14); System.out.println("lrange[0,-1]结果:" + jedis.lrange("list1" , 0 , -1 )); String list = jedis.lindex("list1" , 2 ); System.out.println("list1列表的第三个值:" + list); System.out.println(); Long list15 = jedis.llen("list1" ); System.out.println("list1列表的长度:" + list15); Long list16 = jedis.lrem("list1" , 1 , "2" ); System.out.println("移除list1列表中的一个‘2’:" + list16); System.out.println("lrange[0,-1]结果:" + jedis.lrange("list1" , 0 , -1 )); System.out.println(); String rpoplpush = jedis.rpoplpush("list1" , "list2" ); System.out.println("移除源列表的最后一个值到新的列表:" + rpoplpush); System.out.println("list1结果:" + jedis.lrange("list1" , 0 , -1 )); System.out.println("list2结果:" + jedis.lrange("list2" , 0 , -1 )); Boolean list17 = jedis.exists("list1" ); Boolean list18 = jedis.exists("list3" ); System.out.println("list1是否存在:" + list17); System.out.println("list3是否存在:" + list18); System.out.println(); String list2 = jedis.lset("list2" , 0 , "99" ); System.out.println("设置list2第一个元素为99:" + list2); System.out.println("list2结果:" + jedis.lrange("list2" , 0 , -1 )); System.out.println(); Long linsert = jedis.linsert("list1" , ListPosition.BEFORE, "3" , "4" ); System.out.println("往list1列表中的3前面插入4:" + linsert); System.out.println("list1结果:" + jedis.lrange("list1" , 0 , -1 )); Long linsert2 = jedis.linsert("list1" , ListPosition.AFTER, "1" , "0" ); System.out.println("往list1列表中的1后面插入0:" + linsert2); System.out.println("list1结果:" + jedis.lrange("list1" , 0 , -1 )); System.out.println(jedis.keys("*" )); del = jedis.del("list1" , "list2" ); System.out.println(del); } } >}
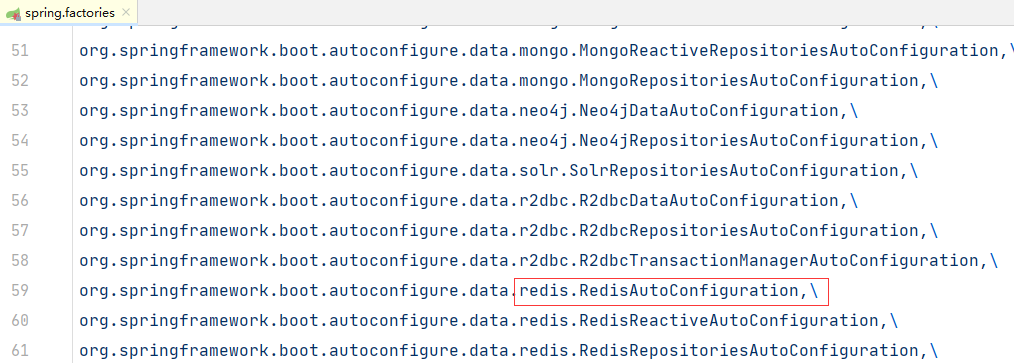
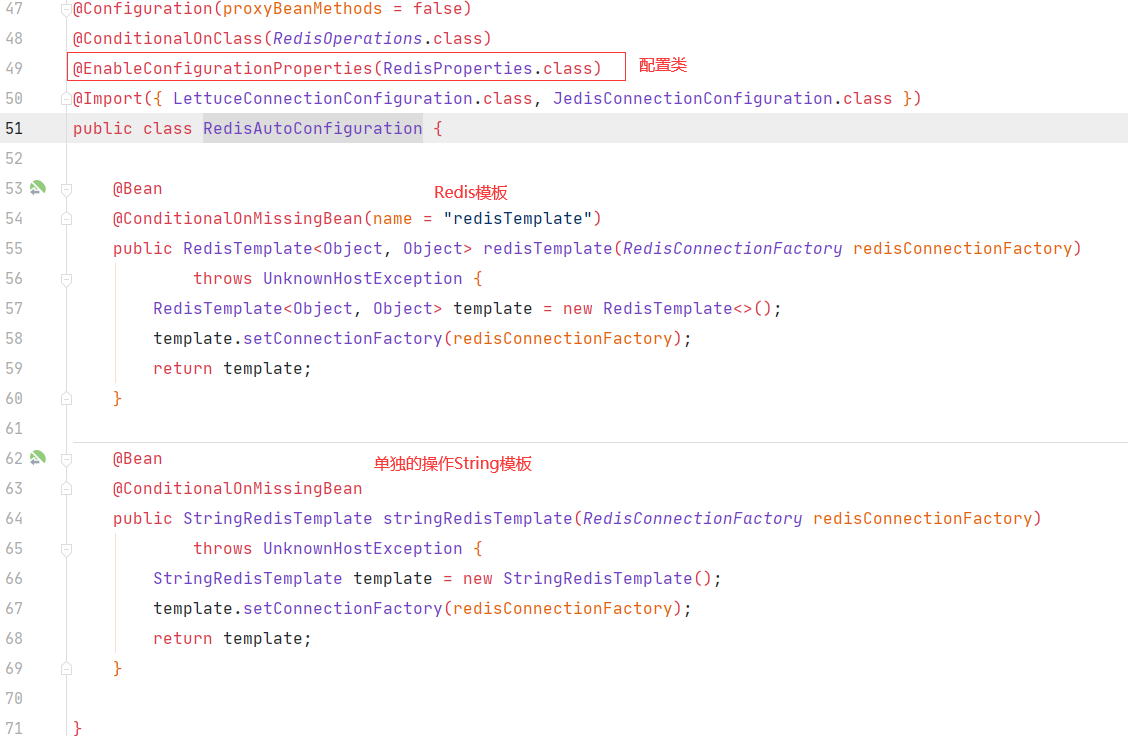
SpringBoot整合 使用SpringBoot-Data–Redis
在SpringBoot2.xhou1,原来的jedis被替换成了lettuce
1 2 3 4 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-redis</artifactId > </dependency >
1 2 3 4 spring: redis: host: 192.168 .45 .113
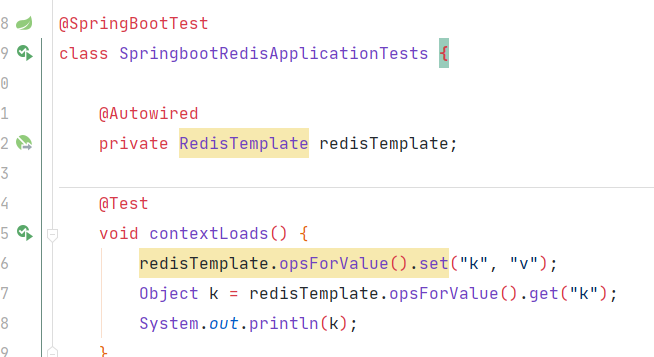
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package cn.this52.springbootdataredis; import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.data.redis.core.RedisTemplate;@SpringBootTest class SpringbootDataRedisApplicationTests @Autowired private RedisTemplate<Object,Object> redisTemplate; @Test void contextLoads () redisTemplate.opsForValue().set("china" ,"中国" ); System.out.println(redisTemplate.opsForValue().get("china" )); System.out.println(redisTemplate.keys("key" )); } }
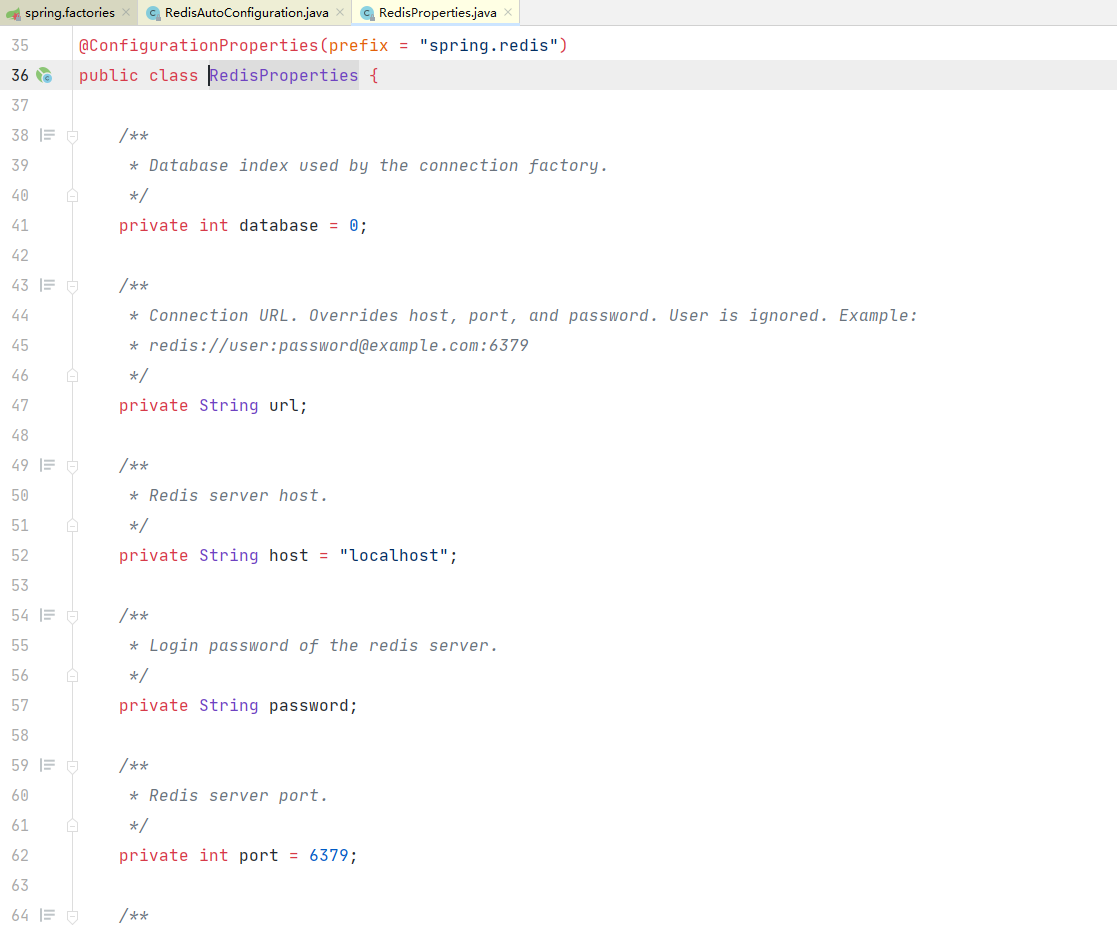
可以看到数据库,主机,端口什么的,然后熟悉的prefix,这里的变量我们都能在配置文件里面配置
Redis.conf 启动服务就需要通过配置文件来启动
单位:k、kb、m、mb、g、bg
配置文件units单位对大小写不敏感
引入INCLUDES
可以引入多个配置文件
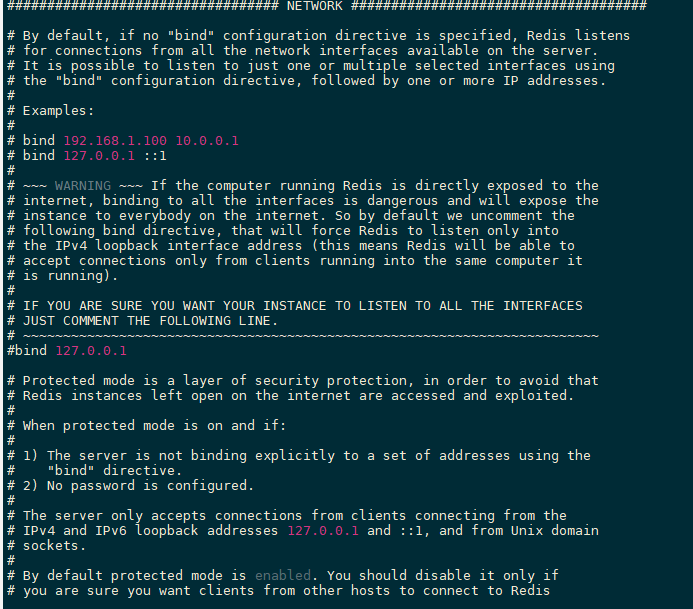
网络NETWORK
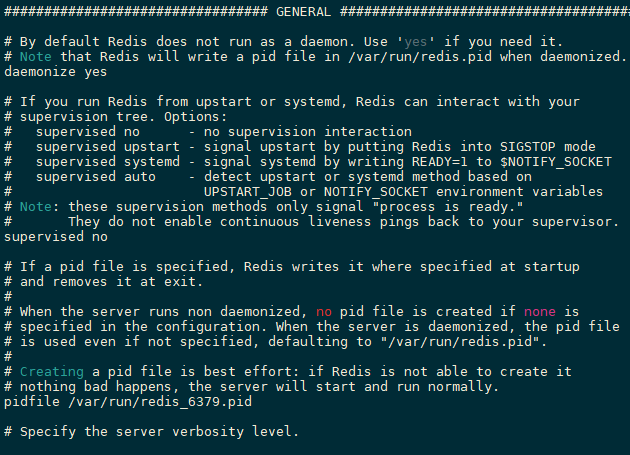
通用GENERAL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 >> >> >> >>160 >>161 >>162 >>163 >>164 >>165 >>166 loglevel notice >>171 logfile "" >>186 databases 16 >>194 always-show-logo yes
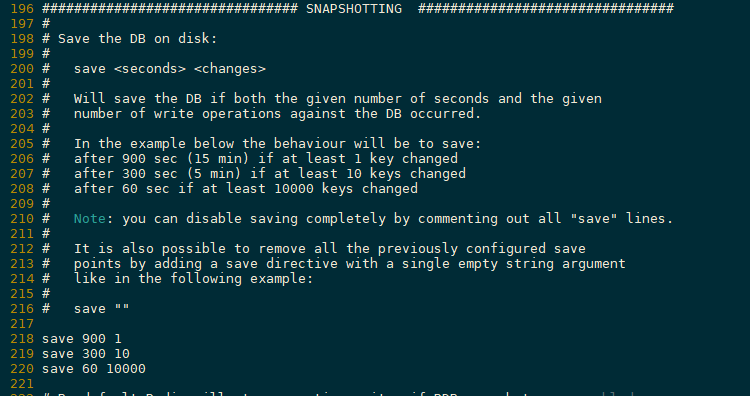
快照SNAPSHOTTING
1 2 3 4 5 6 7 8 9 10 11 >> >> >> >> >> >> >> >> >>
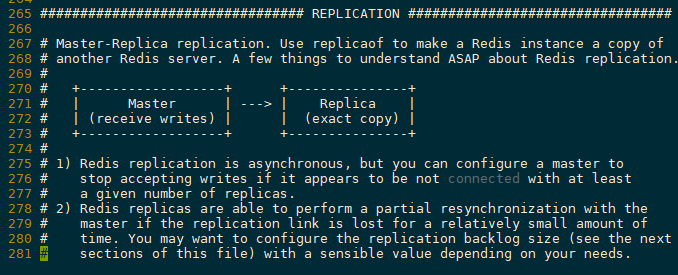
主从复制REPLICATTION
安全SECURITY
也可以通过命令来设置
1 2 3 4 5 6 7 8 9 10 11 12 13 >127.0.0.1:6379> config get requirepass >1) "requirepass" >2) "" >127.0.0.1:6379> config set requirepass root >OK >127.0.0.1:6379> config get requirepass >(error) NOAUTH Authentication required. >127.0.0.1:6379> AUTH root >OK >127.0.0.1:6379> config get requirepass >1) "requirepass" >2) "root" >
客户端CLIENTS
内存管理MEMORY MANAGEMENT
redis 中的默认的过期策略是 volatile-lru 。
设置方式
1 >config set maxmemory-policy volatile-lru
maxmemory-policy 六种方式 1、volatile-lru: 只对设置了过期时间的key进行LRU(默认值)
2、allkeys-lru : 删除lru算法的key
3、volatile-random: 随机删除即将过期key
4、allkeys-random: 随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction :** 永不过期,返回错误
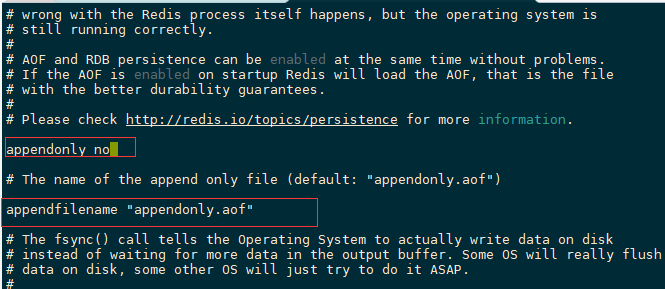
APPEND ONLY MODE AOF配置
1 2 3 4 5 6 > > >728 >729 appendfsync everysec 每秒执行一次 sync >730
Redis持久化 redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。
Redis提供了持久化的机制,分别是RDB和AOF
RDB(REDIS DATABASE)
RDB触发机制
save规则满足的时候
save
是同步的,不会消耗额外内存
会阻塞客户端命令,save时无法处理命令
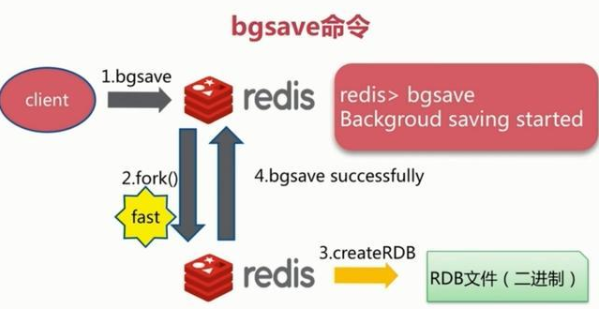
bgsave
异步,需要fork,消耗内存
会在fork发生阻塞,不会阻塞客户端命令
执行FLUSHALL命令的时候
退出redis服务时
恢复rdb文件
只需要简化reb文件放在redis.conf中配置的dir目录即可,redis启动时会自动检查dump.rdb,然后为我们恢复其中的数据
1 2 3 127.0.0.1:6379> CONFIG GET dir 1) "dir" 2) "/usr/local/bin"
优点:
适合大规模的数据恢复
对数据的完整性不高和一致性不高,RBD是很好的选择
缺点:
数据的完整性和一致性不高,因为RBD可能在最后一次备份时宕机了
fork子进程持久化数据的时候比较耗费性能,(因为RDB持久化时会先写入临时文件,然后在替换之前的备份文件,此时内存中存在两份数据)
AOF(Append Only File) 每当有一个写命令过来时,就直接保存在我们的AOF文件中。,就像记录日志一样
AOF保存的是appendonly.aof
append
默认是不开启的,改为yes即可
如果aof文件有错误,客户端是不能连接的,此时我们需要用redis给我们提供的工具来修复它redis-check-aof
这个修复会把错误命令删除掉。
配置
1 2 3 4 5 6 728 729 appendfsync everysec 每秒执行一次 sync 730
优点:
可以每次修改都同步,文件完整性会更好
每秒同步一次,可能会丢失一秒的数据
从不同步,效率最高
缺点:
相对于数据文件来说,aof远远大于rdb,修复的速度也比rdb慢
AOF开启后,支持的写QPS会比RDB支持的写QPS低
AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样
Redis在AOF文件过大时,会fork一个线程自动在后台对数据进行重写,重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的
AOF重写 因为 AOF 的运作方式是不断地将命令追加到文件的末尾, 所以随着写入命令的不断增加, AOF 文件的体积也会变得越来越大。
举个例子, 如果你对一个计数器调用了 100 次 INCR key , 那么仅仅是为了保存这个计数器的当前值, AOF 文件就需要使用 100 条记录(entry)。
然而在实际上, 只使用set key value命令已经足以保存计数器的当前值了, 其余 99 条记录实际上都是多余的。
Redis2.4会自动触发AOF重写
扩展文档
Redis发布与订阅 Redis 通过 PUBLISH 、 SUBSCRIBE等命令实现了订阅与发布模式, 这个功能提供两种信息机制, 分别是订阅/发布到频道和订阅/发布到模式。
频道的订阅与信息发送 Redis 的 SUBSCRIBE命令可以让客户端订阅任意数量的频道, 每当有新信息发送到被订阅的频道时, 信息就会被发送给所有订阅指定频道的客户端。
频道:channel1
三个客户端:client1,client2,client5
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
订阅端:
1 2 3 4 5 6 7 8 9 10 11 12 127.0.0.1:6379> SUBSCRIBE aurora Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "aurora" 3) (integer ) 1 1) "message" 2) "aurora" 3) "msg" 1) "message" 2) "aurora" 3) "hello,aurora"
频道端:
1 2 3 4 127.0.0.1:6379> PUBLISH aurora msg (integer ) 1 127.0.0.1:6379> PUBLISH aurora hello,aurora (integer ) 1
Redis主从复制 概念 主从复制,读写分离。大部分情况下都是在进行读操作,可以减缓服务器的压力
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点,从节点也能有多个从节点。
主从复制的作用
主从复制的作用主要包括:
数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
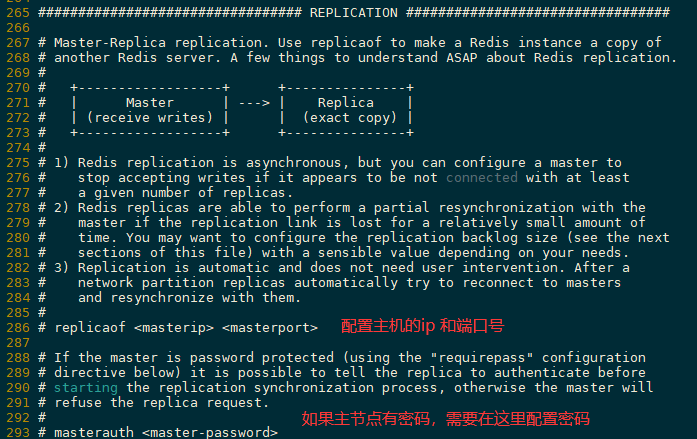
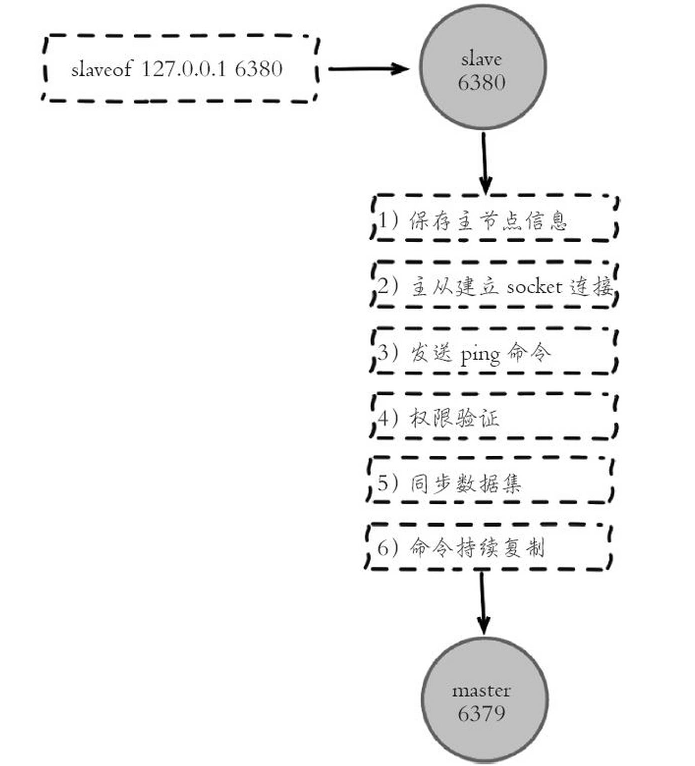
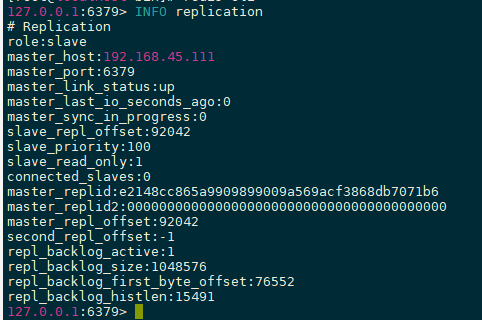
环境配置 主从复制,只配置从节点,不需要配置主节点
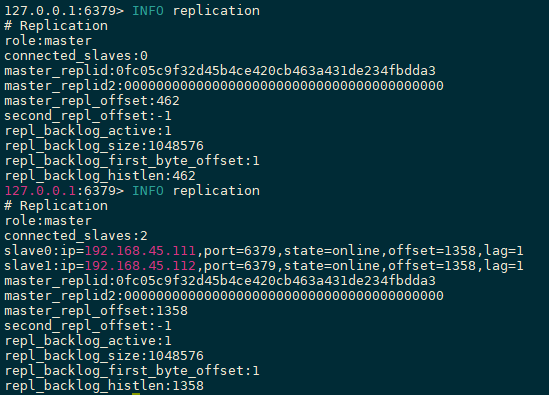
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 127.0.0.1:6379> INFO replication role:master connected_slaves:0 master_replid:8ef6b543c26f2812682f22d2ee30423baca85fe8 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:0 second_repl_offset:-1 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 127.0.0.1:6379>
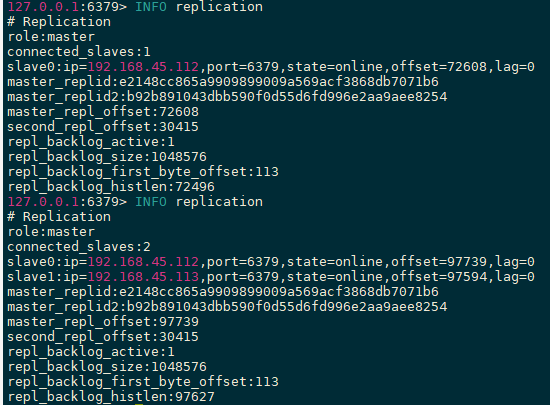
一主二从
注意事项:
主节点的bind需要配置为0.0.0.0或者注释,不然无法挂载
主节点需要关闭保护模式,或者在从节点中配置masterauth
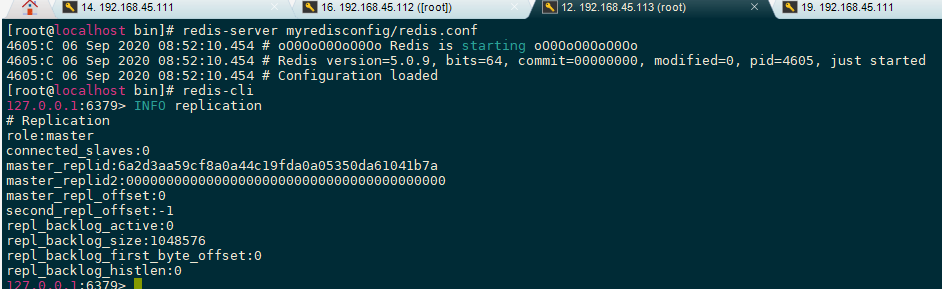
主节点[192.168.45.113]
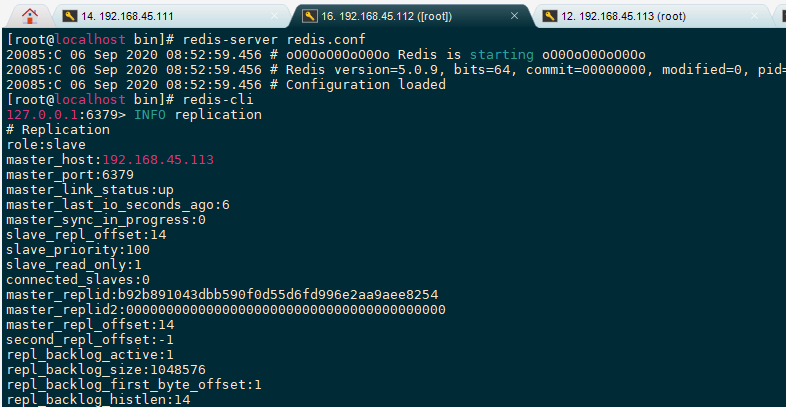
从节点[192.168.45.111]
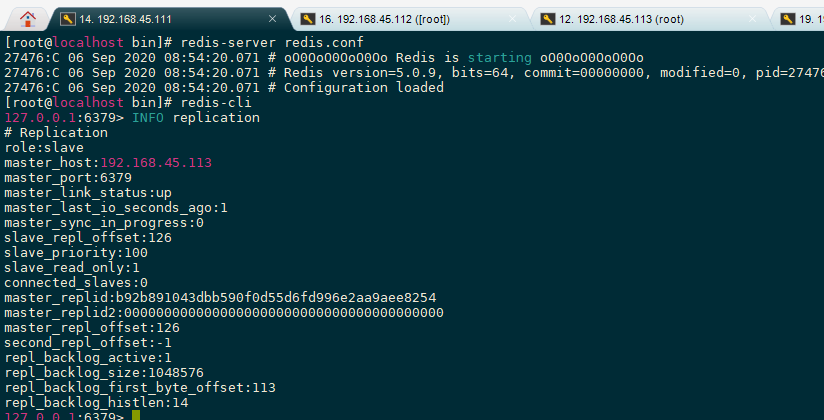
从节点[192.168.45.112]
真实的主从配置应该去配置文件中配置,才能永久生效。命令开启的只是暂时的
主节点挂掉后恢复,依然还是主节点,从节点会自动连接上来
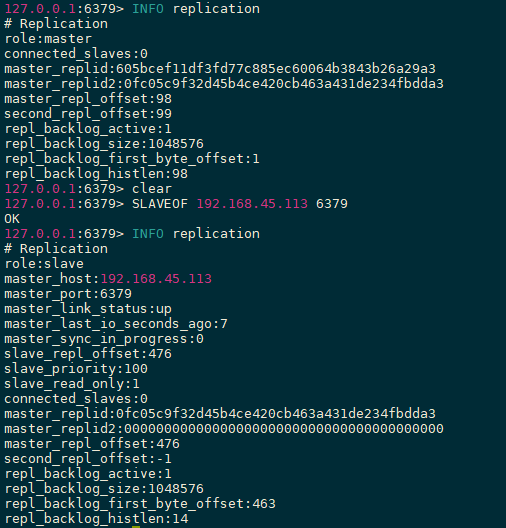
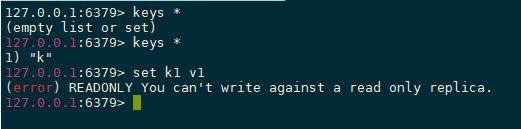
主写从读 主机负责写,从机负责读,从机是不能写的
复制原理
slave启动成功连接到master后会发送sysnc命令,master启动一个后台进程将数据库快照保存到RDB文件中(此时如果生成 RDB 文件过程中存在写数据操作会导致 RDB 文件和当前主 redis 数据不一致,所以此时 master 主进程会开始收集写命令并缓存起来,最后再把转发给slave。),然后发送给slave,slave将文件保存到磁盘上,然后恢复到内存中。
后续 master 收到的写命令都会通过开始建立的连接发送给 slave。
当 master 和 slave 的连接断开时 slave 可以自动重新建立连接。如果 master 同时收到多个 slave 发来的同步连接命令,只会启动一个进程来写数据库镜像,然后发送给所有 slave。
全量复制和增量复制 在Redis2.8前,每次都会全量复制,当从节点停止运行后,在启动可能只有少量数据不同步,此时从节点依旧会复制全部数据,这样性能很低
之后会判断是否是首次同步,不是首次master只会发送非同步的数据,这样就提高了性能。
扩展:
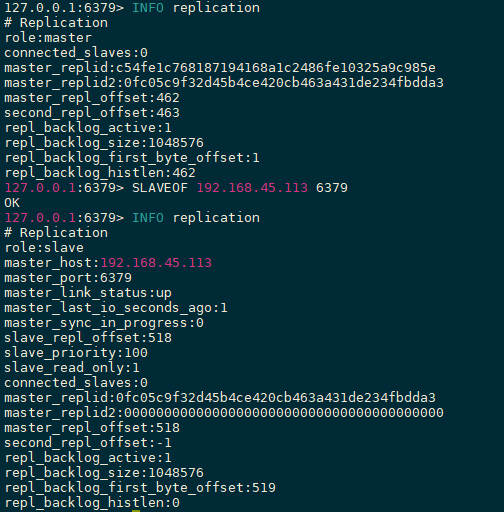
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master 的 runid(机器标识,随机生成的一个串) 和 offset(数据偏移量,如果offset主从不一致则说明数据不同步),主机验证 runid 和 offset 是否有效,runid 相当于主机身份验证码,用来验证从机上一次连接的主机,如果 runid 验证未通过则,则进行全同步,如果验证通过则说明曾经同步过,根据 offset 同步部分数据。
扩展: 手动选举
当主节点挂掉的时候我们可以使用SLAVE NO ONE命令让从节点变成主节点,其他从节点会自动选择主节点。
主节点恢复后只是一个单独的节点。
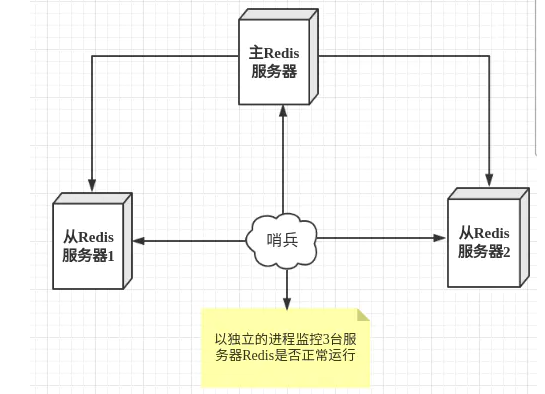
哨兵模式 简介 主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。 这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式 。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
哨兵作用
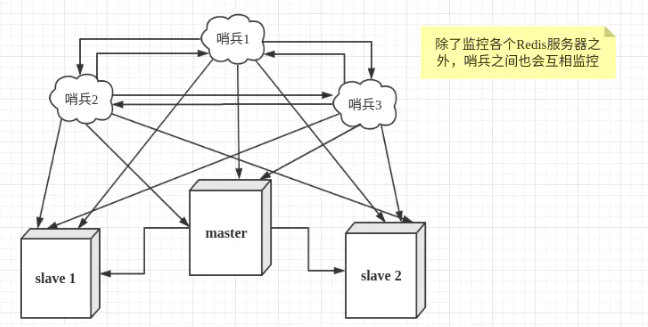
哨兵也可能会出现问题,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,形成多哨兵模式。
实践测试
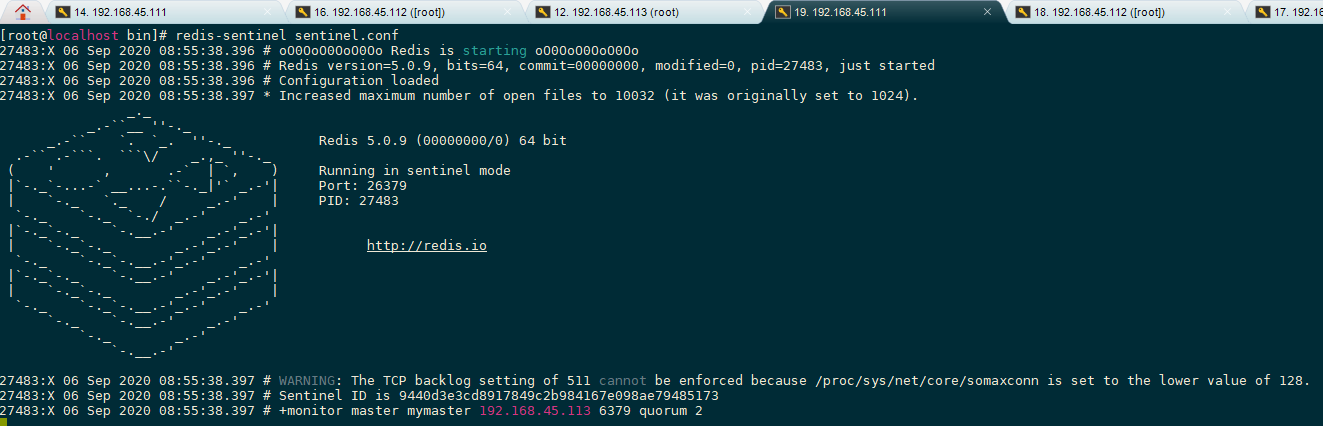
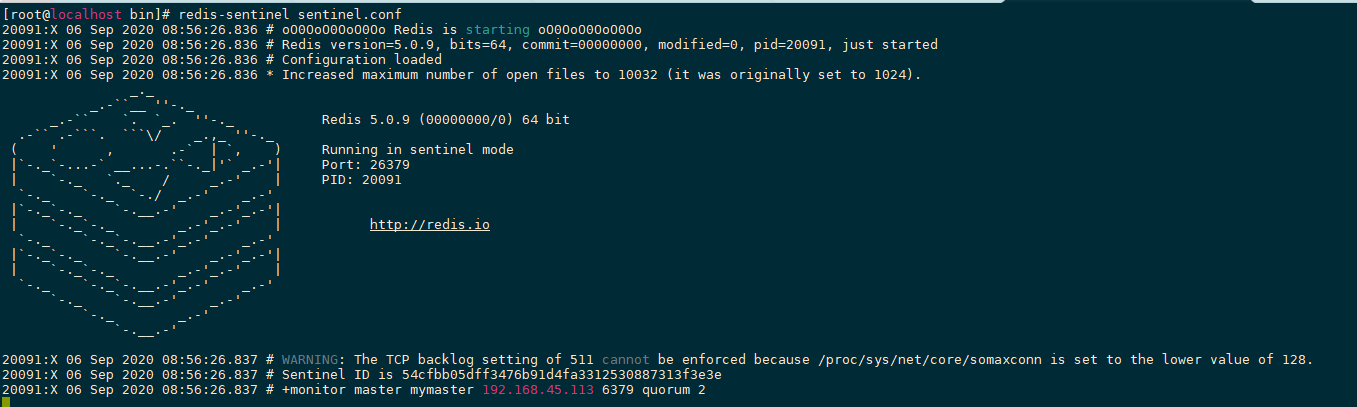
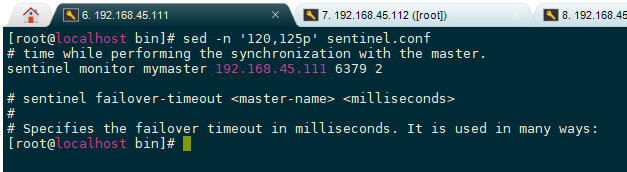
首先把redis目录里面的sentinel.conf拷贝一份过来
然后配置一下主节点host等信息
先启动主服务器redis服务,然后启动从服务器,最后开启哨兵
此时没有任何从节点
112连接上主节点
111连接上主节点
开启三个主机的哨兵
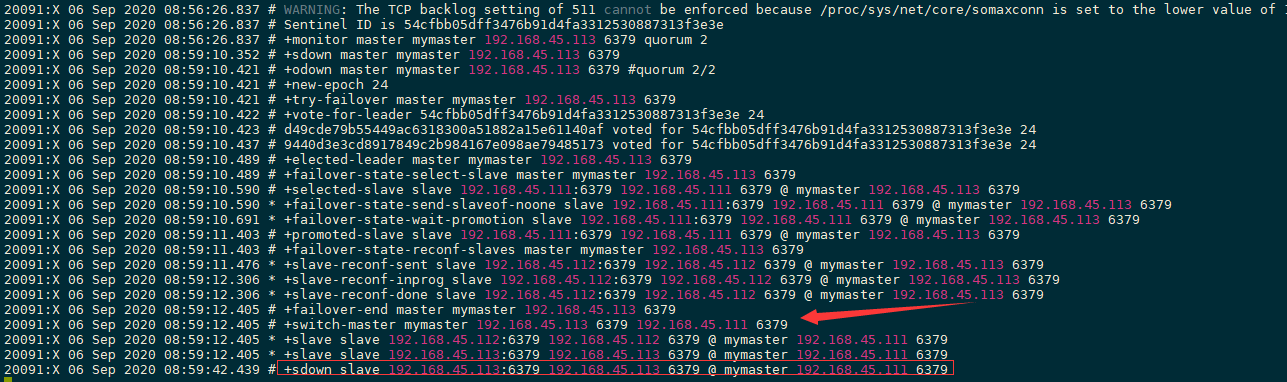
测试主从复制没有问题,然后测试113宕机
可以看到主节点从113变成了111
然后重启113的服务
选取主节点后,哨兵会自动修改sentinel.conf中的监控配置
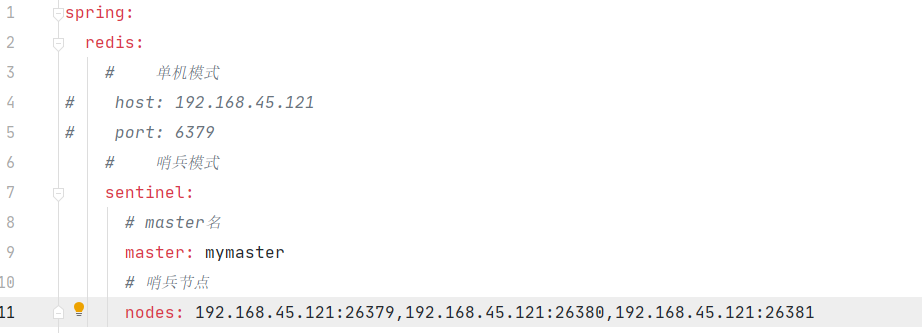
SpringBoot操作哨兵模式
配置哨兵模式
代码测试没问题
哨兵模式优缺点 优点:
哨兵集群是基于主从复制的,所有主从复制的优点他都有
高可用,在主节点故障时能实现故障转移
哨兵模式就是主从复制的升级,手动到自动,更加健壮
缺点:
没办法做到水平扩展
主服务器宕机后,故障转移那段时间,服务是不可用的
依旧无法解决单节点并发、吞吐量,物理上限等问题
运维复杂,哨兵模式配置起来其实是很麻烦的
Cluster集群
实现高可用
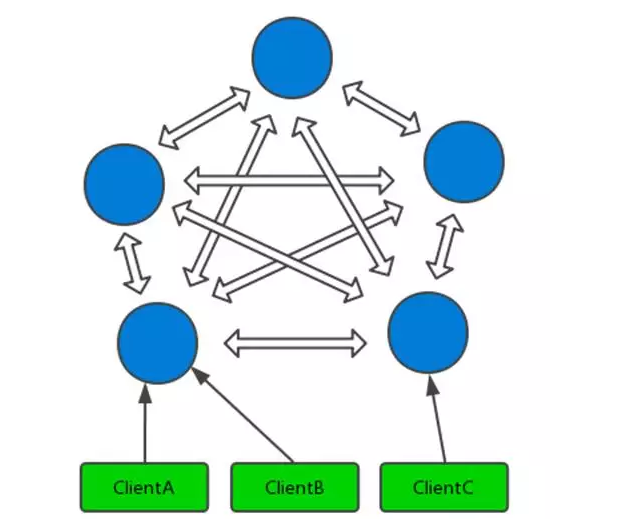
架构特点:
所有的 redis 节点彼此互联 (PING-PONG 机制),内部使用二进制协议优化传输速度和带宽。
节点的 fail 是通过集群中超过半数的节点检测失效或者某个节点主从全挂时才生效。
客户端与 redis 节点直连,不需要中间 proxy 层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
redis-cluster 把所有的物理节点映射到 [0-16383]slot 上
slot = CRC16(key)& 16383
Redis 集群一般由 多个节点 组成,节点数量至少为 6 个,才能保证组成 完整高可用 的集群
集群搭建
1 2 3 4 5 6 7 8 9 10 11 bind 0.0.0.0 port 7000 daemonize yes pidfile /var/run/redis_7000.pid dbfilename dump7000.rdb appendonly yes appendfilename "appendonly7000.aof" cluster-enabled yes cluster-config-file nodes-7000.conf cluster-node-timeout 5000
1 2 3 4 5 6 7 8 9 10 11 12 vim redis-start.sh redis-server rediscluster/redis-7000.conf redis-server rediscluster/redis-7001.conf redis-server rediscluster/redis-7002.conf redis-server rediscluster/redis-7003.conf redis-server rediscluster/redis-7004.conf redis-server rediscluster/redis-7005.conf chmod +x redis-start.sh
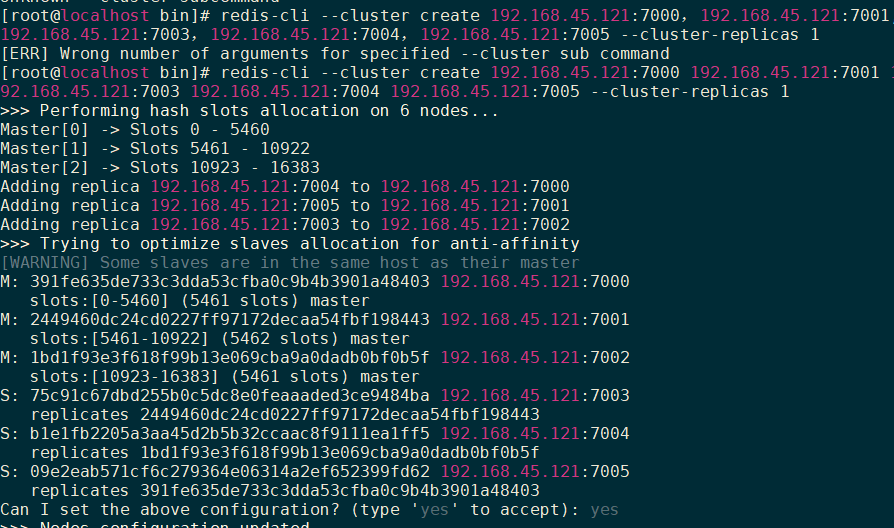
1 2 3 4 5 6 ./redis-start.sh redis-cli --cluster create 192.168.45.121:7000 192.168.45.121:7001 192.168.45.121:7002 192.168.45.121:7003 192.168.45.121:7004 192.168.45.121:7005 --cluster-replicas 1
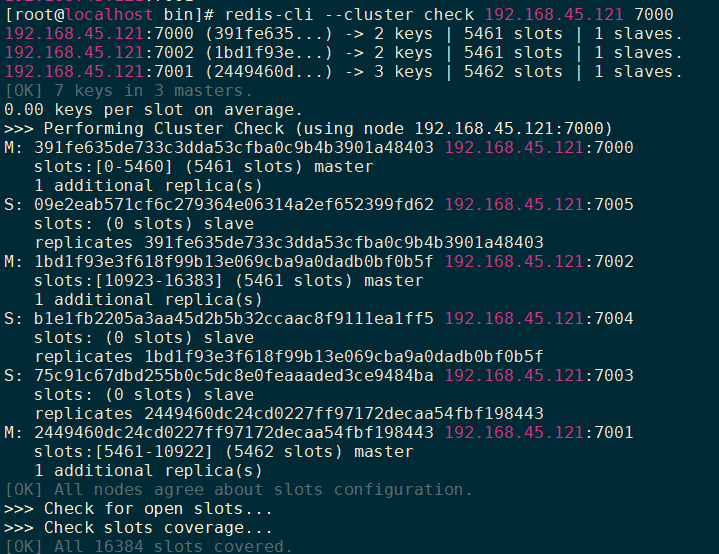
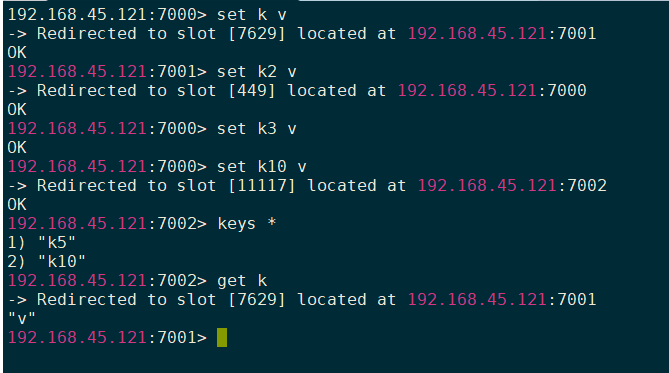
集群测试 1 2 3 4 redis-cli --cluster check [host]:[port] redis-cli --cluster check 192.168.45.121:7001
1 2 3 4 redis-cli -c -h [host] -p [port] redis-cli -c -h 192.168.45.121 -p 7000
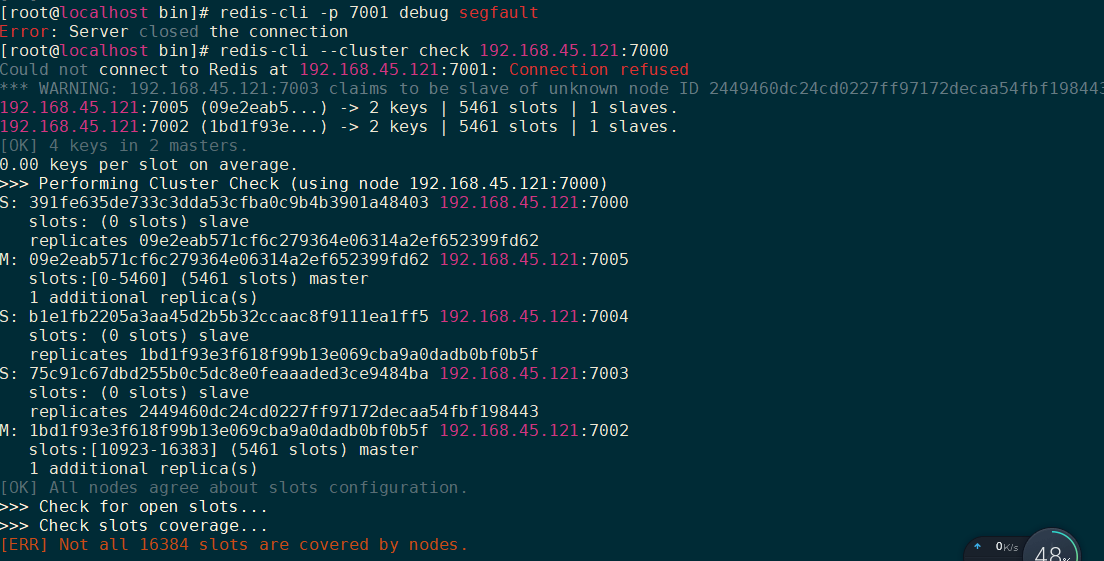
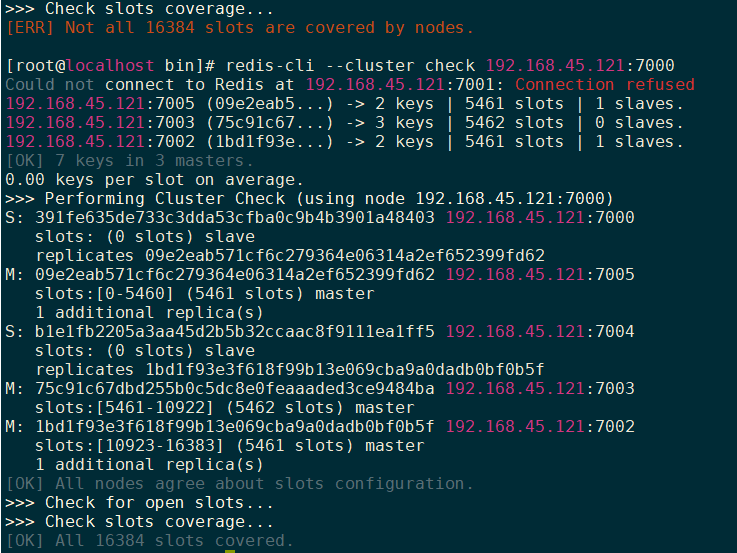
集群故障切换测试
1 2 3 redis-cli -p 7001 debug segfault
1 2 3 redis-cli --cluster add-node [host:port] [host:port] redis-cli --cluster add-node 192.168.45.121:7006 192.168.45.121:7000
redis-cli -cluster命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 redis-cli --cluster help Cluster Manager Commands: create host1:port1 ... hostN:portN --cluster-replicas <arg> check host:port --cluster-search-multiple-owners info host:port fix host:port --cluster-search-multiple-owners reshard host:port --cluster-from <arg> --cluster-to <arg> --cluster-slots <arg> --cluster-yes --cluster-timeout <arg> --cluster-pipeline <arg> --cluster-replace rebalance host:port --cluster-weight <node1=w1...nodeN=wN> --cluster-use-empty-masters --cluster-timeout <arg> --cluster-simulate --cluster-pipeline <arg> --cluster-threshold <arg> --cluster-replace add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id <arg> del-node host:port node_id call host:port command arg arg .. arg set-timeout host:port milliseconds import host:port --cluster-from <arg> --cluster-copy --cluster-replace help For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
SpringBoot操作Cluster
Redis缓存穿透和雪崩 缓存穿透
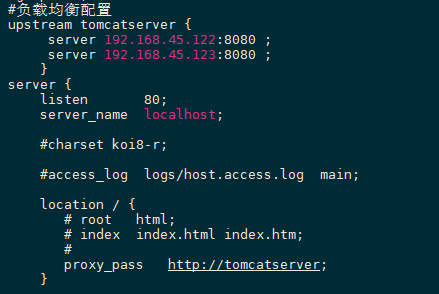
Redis实现分布式Session 管理机制
redis的session管理是利用spring提供的session管理解决方案,将一个应用的session存储到redis上,整个应用session请求都回去redis中获取sessin数据
开发Session管理 1.引入依赖 1 2 3 4 <dependency > <groupId > org.springframework.session</groupId > <artifactId > spring-session-data-redis</artifactId > </dependency >
2.配置RedisSession 1 2 3 4 5 6 7 8 9 package cn.this52.sessionredis.config;import org.springframework.context.annotation.Configuration;import org.springframework.session.data.redis.config.annotation.web.http.EnableRedisHttpSession;@Configuration @EnableRedisHttpSession public class RedisSessionManager }
3.配置redis集群 1 2 3 4 spring: redis: cluster: nodes: 192.168 .45 .121 :7000,192.168.45.121:7001,192.168.45.121:7002,192.168.45.121:7003,192.168.45.121:7004,192.168.45.121:7005
4.测试代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package cn.this52.sessionredis.controller;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.RequestMapping;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.IOException;import java.util.ArrayList;import java.util.List;@Controller public class TestController @RequestMapping("test") public void tes (HttpServletRequest request, HttpServletResponse response) throws IOException List<String> list = (List<String>) request.getSession().getAttribute("list" ); if (list == null ) { list = new ArrayList<>(); } list.add("111" ); request.getSession().setAttribute("list" , list); response.getWriter().println("size=>>:" + list.size()); response.getWriter().print("seesionid=>>:" + request.getSession().getId()); } @RequestMapping("te/logout") public void logout (HttpServletRequest request) throws IOException request.getSession().invalidate(); } }
5.打war包测试 1 2 3 4 5 6 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-tomcat</artifactId > <scope > provided</scope > </dependency >
打包时报错Failed to execute goal org.apache.maven.plugins:maven-war-plugin:2.2:war (default-war) on project session-redis: Error assembling WAR: webxml attribute is required (or pre-existing WEB-INF/web.xml if executing in update mode)
引入插件解决
1 2 3 4 5 6 7 8 <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-war-plugin</artifactId > <version > 2.6</version > <configuration > <failOnMissingWebXml > false</failOnMissingWebXml > </configuration > </plugin >
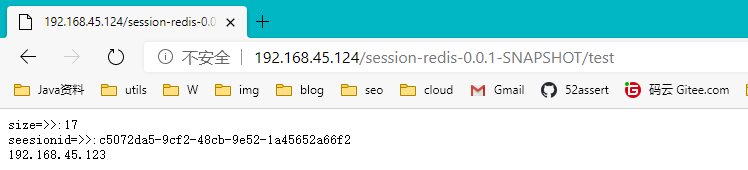
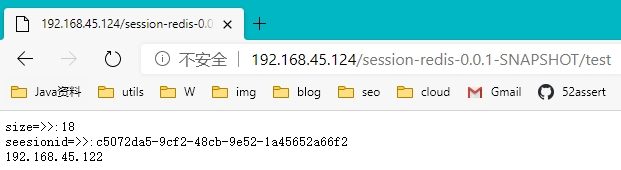
6.部署到Linux
测试OK
springboot Rdis集群 当一个redis节点宕机后,程序依旧报错command timeout,还未解决